Table of Contents

Four years into building Customaite.ai, we made the decision to migrate away from reactive programming. Here’s why, and how Java’s Virtual Threads made it possible without needing to trade-off performance.
Recently I gave a talk on how the new Java Virtual Threads feature allowed us to simplify the codebase at Customaite. I spoke about our journey from migrating away from a reactive framework (Quarkus Mutiny) and which additional patterns we needed to address some gaps in the standard library. The discussion afterwards, with Burr Sutter, went into detail on the origin of the reactive web server and why complicated reactive frameworks may not make sense for you.
You can find the video link below, but for those who prefer the written word I’ve included a high level summary. You may wish to jump to the relevant section in the talk if you find it too concise.
Github repository for the code segments
The reactive challenges
Customaite.ai is built with the Java Quarkus framework. At the time Quarkus promoted a custom reactive framework called Mutiny, as a way to achieve higher concurrency. To understand why this may or may not matter for your use case, we’ll need to talk about threading mechanisms on Java.
In the standard web server approach, a worker pool of java platform threads is spun up, each tied to one OS thread. As requests come in, they are being served by one of those platform threads. If those threads are blocked waiting for I/O such as making a call to an external service, the OS scheduler will schedule a different worker thread. But as your platform threads are being used up, additional incoming work needs to wait until one becomes available or a new one is created.
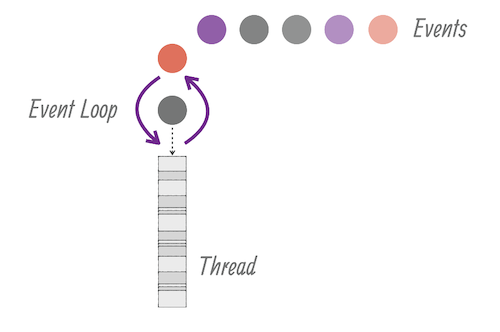
Quarkus is built on the vert.x web-server, which works with an event loop (such as Node.js). A couple of event loop threads process code that’s written to be reactive, and if it encounters a blocking segment, it will continue to the next event instead. Code that’s not written to be reactive can be explicitly called to be executed in a ‘worker thread’, which will follow the same principle as the platform threads mentioned earlier.
This event-driven way allows the event loop to be performant and reduce idle waiting time. The downside is that reactive code is harder to write and read, and it’s easy to shoot yourself in the foot. If the event loop does execute blocking code, your performance will suffer because there are just a few event loop threads.
There’s a steep learning curve associated with reactive frameworks, and debugging was another nightmare as the stack traces are difficult to debug. We also encountered issues with disappearing logs, where the solution was often to rewrite a piece of reactive code in the synchronous variant.
To reap the benefits of reactive code, there’s also a need for it to be reactive all the way down, and the entire ecosystem (such as hibernate reactive, for writing reactive code to the database) wasn’t production ready at the time and caused us several headaches.
Virtual threads and Quarkus
Virtual threads were officially introduced with Java Development Kit version 21, launched in September 2023. Virtual threads follow a similar model as Kotlin coroutines or Go’s Goroutines: lightweight threads that are faster to spin up and which consume fewer memory resources (order of KB vs MB)
The basic principle is that it could allow you to create one such lightweight thread for each request or subtask. If one of those lightweight threads is blocked as it waits for I/O, the scheduler will execute a different thread instead until it is unblocked.
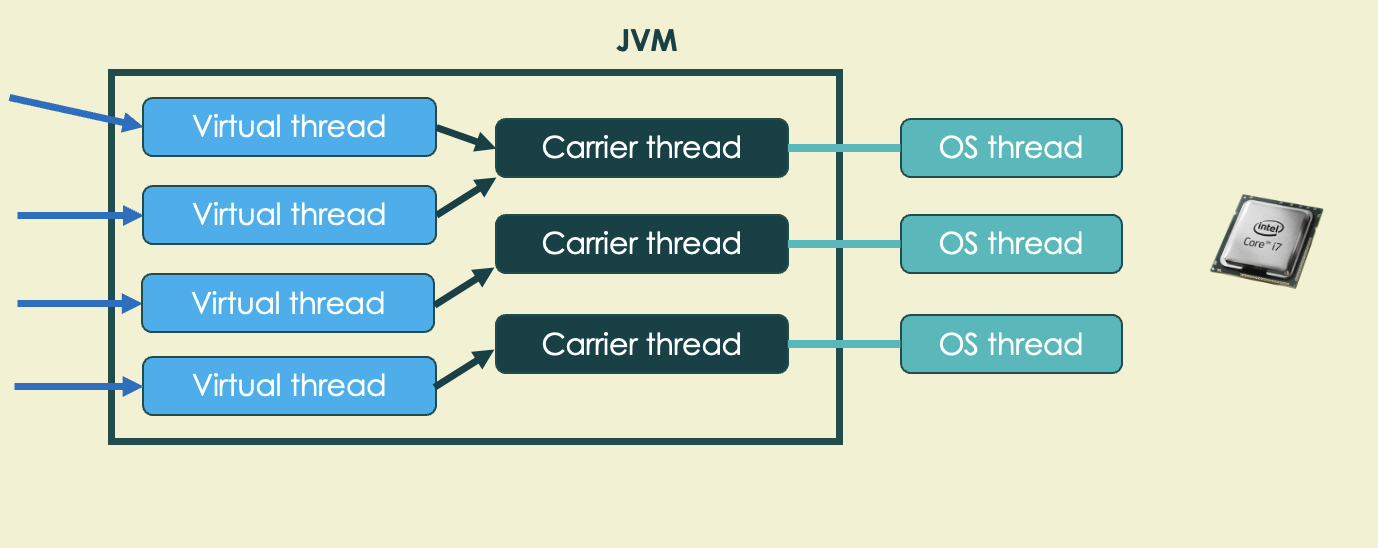
This allows the user to still write simple, familiar, synchronous code that works with existing blocking libraries, while offering another way to be efficient around blocking I/O and increasing throughput.
In Quarkus it’s as easy as adding an annotation @RunOnVirtualThread to ensure an incoming HTTP request or consumed message is run on a new virtual thread instead of being continued on the event loop.
In the talk I show a simple demo of three types of endpoints, one that’s written to be reactive, and that’s written to be ‘blocking’ using the traditional way, and one that uses virtual threads. A script launches requests with increased load. While the reactive endpoint can tackle more http requests before slowing down too much than the synchronous endpoint, the virtual thread approach can match it for this simple scenario.
So similar performance benefits, with much simpler code. What’s the catch?
You will still need additional mechanisms for using virtual threads to distribute work, for tasks that you may want to run in parallel such as making different API calls before returning a response. We’ll cover these in the next section.
If your work is primarily cpu-intensive rather than I/O bound, using virtual threads may not offer additional benefits. You will not be able to optimize idle time as much. The cost may not be high however.
And finally, there is a risk of the carrier thread being ‘pinned’. To allow the JVM scheduler to assign a different virtual thread to a carrier thread, the virtual thread should be able to be ‘released’. It can’t do it if it’s running in a mutex such as a
synchronizedblock.
The ‘pinning risk’ was widely touted when JDK 21 released, but we never encountered this issue. Quarkus offered support for virtual threads as soon as they were able to upgrade their database transaction manager that no longer used synchronized blocks. With Java 24, the risk of pinning was further reduced with JEP 491.
Additional patterns to make virtual threads work
For scheduling incoming http requests or asynchronous messages, adding the @RunOnVirtualThread annotation on a method in Quarkus is sufficient.
If you also want to schedule outbound flows on Virtual Threads, so that you can for example do a request to two services at the same time such as retrieving User Information and Order Information, there’s two additional features you can use.
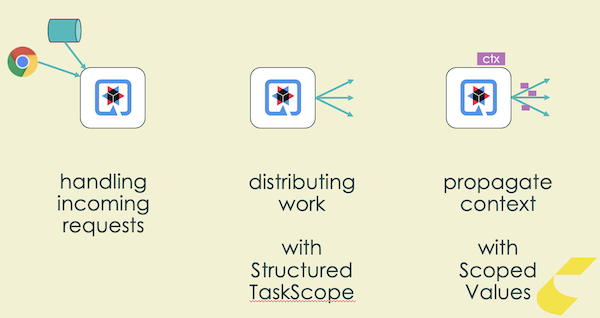
They’re called Structured Concurrency and Scoped Values. Both are preview features, meaning they are ready to be used in production but their APIs may change, and have done so in the past. For this reason you should encapsulate them in a shared library.
Structured concurrency is a way of launching tasks in one scope. You can specify whether the scope should end early based on the first failure, or on the first success. The main limitation today is that these are the only strategies you can use.
Here’s how we handle these scenarios in practice:
1try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
2
3 // Invoking scope.fork() will start the task immediately on a new virtual thread
4 var userProfileTask = scope.fork(() -> {
5 return usersService.getUserProfileInformation()
6 });
7
8 var orderTask = scope.fork(() -> {
9 return orderService.getUserOrders()
10 });
11 // Code will wait at this point for the scope to finish.
12 scope.join();
13 // or if you want to impose a deadline,
14 // scope.joinUntil(Instant.now().plusSeconds(30));
15 scope.throwIfFailed();
16 var orders = orderTask.get();
17 var userProfile = userProfileTask.get();
In our application we set context specific to the request via @RequestScoped beans (singletons). However, these new virtual threads are no longer associated with Java ‘Requests’ and RequestScoped context. Fortunately a new mechanism has been introduced in order to assign task-scoped state that will be set for any tasks started in a scope (even if started from one of the virtual threads). This is called Scoped Value.
You can define a Scoped Value as a static variable, e.g.
1@ApplicationScoped
2public class ContextHolder {
3
4 public final static ScopedValue<ContextData> SCOPED_CONTEXT = ScopedValue.newInstance();
5 // Reference to a RequestScoped bean. We will copy its value to the scoped value when starting parallel tasks.
6 private final RequestContext requestContext;
7
8 // Return the correct context either from a request scoped bean or from the scoped values, if it is set.
9 public ContextData getRequestContext() {
10 if (SCOPED_CONTEXT.isBound())
11 return SCOPED_CONTEXT.get();
12 return requestContext.getContextData();
13 }
14}
And then set this instance value when you’re calling the Structured Scope, by wrapping the code in a ScopedValue.where
1
2 ScopedValue.where(
3 contextHolder.SCOPED_CONTEXT, contextHolder.getRequestContext())
4 .run(
5 () -> {
6 try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
7 // Same code as before.
8 // Now when a virtual thread accesses the scoped value, it will have the values you specified above
9 var ctx = contextHolder.SCOPED_CONTEXT; // Set to what was in contextHolder.getRequestContext()
10 }
11 });
As mentioned before, the API structure for both structured concurrency and scoped value has slightly changed across the different preview iterations.
You can also still use Executors to schedule work, but the above features show the way forward in the Java system and are simpler to use. Its main advantage is that it’s more apparent to which ‘scope’ a set of tasks belong to, and what should happen if e.g. one of them fail or if an overall deadline has been reached.
One final pattern to mention: you may need to give your observability tools some help when transitioning code to virtual threads. We use Datadog, which requires the traceId context to be passed along, as well as variables that we rely on in logging to be included in the MDC. In our shared library which encapsulates the calls to StructuredScope, we wrap the actual task invocations with the following code in order to set the trace context manually and set the MDC (based on the context passed along via the Scoped Value)
1public <T> Callable<T> wrapMdcAndTraceContext(Callable<T> task) {
2 Span currentSpan = GlobalTracer.get().activeSpan();
3
4 return () -> {
5 // Activate the span within the virtual thread with the parent span, to ensure apm traces are linked from lambdas
6 try (Scope _ = GlobalTracer.get().activateSpan(currentSpan)) {
7 return setMdc(task);
8 }
9 };
10}
11
12public <T> T setMdc(Callable<T> task) throws Exception {
13 // MDCLogRequest is a helper class that adds variable from the context to MDC, so that they are added to logs and picked up by Datadog.
14 mdcLogRequest.setMdc(domainContextHolder.getContext());
15 return task.call();
16}
Migration gotchas
Using virtual threads in conjunction with a multi-tenant environment has worked well for us for the past two years, using the patterns mentioned above. Migration was relatively easy, as Quarkus allows the use of both reactive and non-reactive code in the same stack.
There were some gotchas: if you are still using reactive libraries (e.g. for sending REST requests or database calls with reactive-hibernate), Quarkus would still switch to the event loop after receiving the response despite the code being called in worker threads. Replace these libraries first with the non-reactive variant. Check your logs and group them by @threadName to verify where the code is being run. Running synchronous code on the Vert.x event loop will tank your service’s performance.
Lessons learned
Doing the migration was definitely worth the hassle to us. From a maintenance point of view debugging and making changes is much easier. You spend a lot more time reading code than writing code, and being able to spot issues at a glance is a godsend for new and veteran engineers in the team alike.

When performance becomes a trade-off compared to code complexity, make sure to be specific about ‘what kind’ of performance gains are expected and which bottlenecks they alleviate. When Customaite started out and was looking for product/market fit, would the theoretical gains from improved request load prove to be necessary?
At this stage, speed to market becomes more valuable and may make more sense until better solutions (such as virtual threads) come along and your system’s actual performance limitations become more clear.
I hope this guide proved useful to you, and if you have any questions feel free to ping me.
Get notified of new posts by subscribing to the RSS feed or following me on LinkedIn.